21 mai 2018

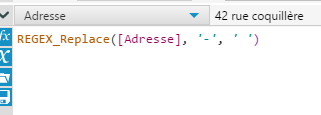
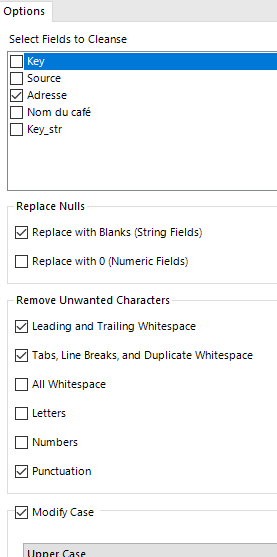
L’outil Fuzzy Match a un côté ‘Magique’. Pour rapprocher les valeurs d'un champ, si ce dernier n’est pas propre, impossible d'utiliser des jointures. C’est ce qui peut arriver avec des valeurs entrées à la main par exemple : noms, adresses, numéro de téléphone… le lundi on a enregistré un Matthieu Dupont et le mercredi un Mathieu Dupond. Cela peut aussi être le cas avec un catalogue de produits, d’offres ou de campagnes identifiées par des libellés, etc.Si les jointures ne fonctionnent pas, reprendre les valeurs à la main nécessite du temps, trop de temps.
![]()

![]()


Rien ne vous empêche de tester différentes configurations à partir d'un sous ensemble de données.D'ailleurs, n'hésitez pas à copier votre outil de matching et à en lancer plusieurs à la fois, avec différentes configurations, afin de comparer directement les outputs.
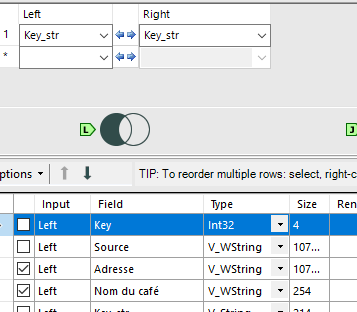
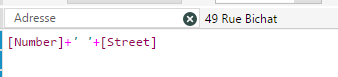
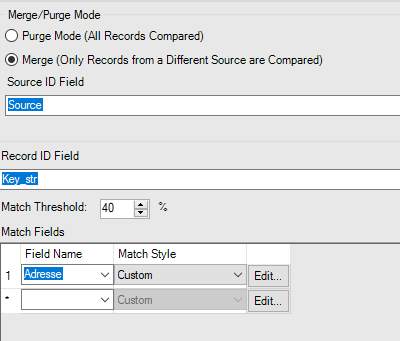
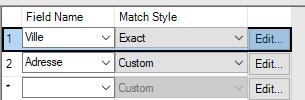
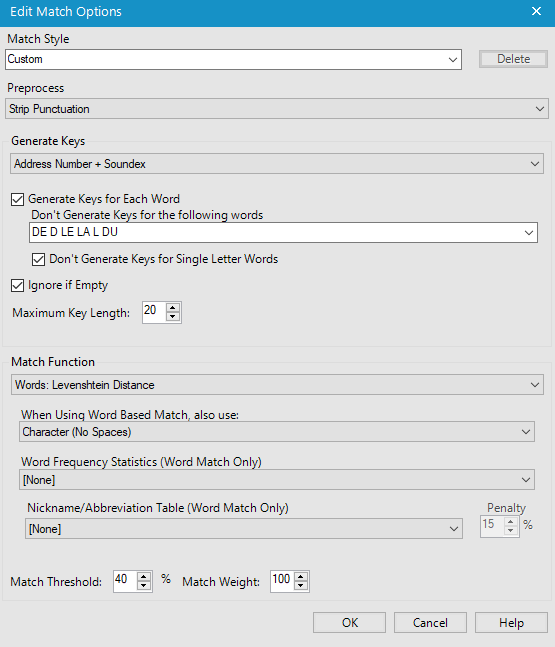
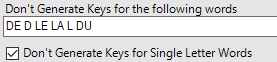
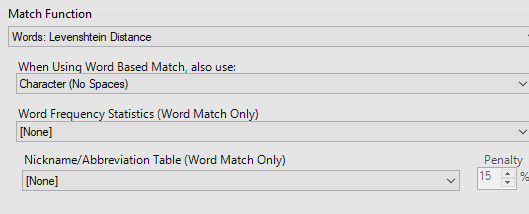
Enfin les statistiques sur la fréquence des mots sont basées sur la lange anglaise (les adresses et les surnoms communs aux Etats-Unis). Il y a peu de chances que cela fonctionne sur des données françaises. St (abréviation de Street : rue) va être très présent dans les adresses aux US et aura donc un poids moins important. Le St en France n’a pas la même signification. La longueur maximale de la clef de matching est également importante.Si vous souhaitez matcher des mots tels que hippopotomonstrosesquipédaliophobique,ou si vous ne savez pas quoi choisir, vous pouvez laisser le 20 par défaut. Avec 20, il matcherai tous les mots ayant au moins 20 lettres en commun avec hippopotomonstrosesquipédaliophobique (dans ce cas il faudrait mettre 37 pour avoir le mot entier). Avec une clef de taille 20 vous avez déjà peut de chance de rapprocher des mots différents. Si en revanche vous forcez une clef plus petite, par exemple 2 vous aurez un match exact entre FRA et FR mais aussi UFR … Dans certains cas, il peut être intéressant de baisser la taille de la clef. Encore une fois, cela dépend de vos données ! Enfin pour chacun des champs matchés, vous pouvez définir un threshold et un poids :
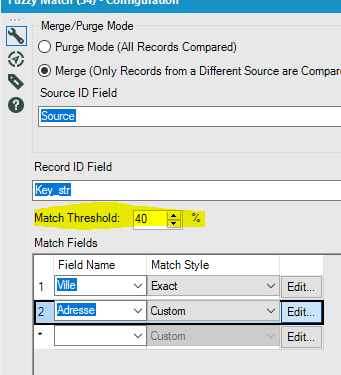
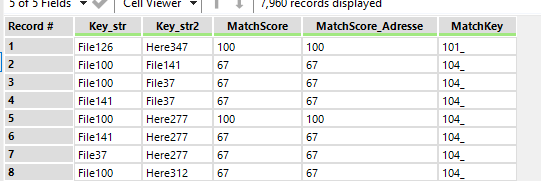
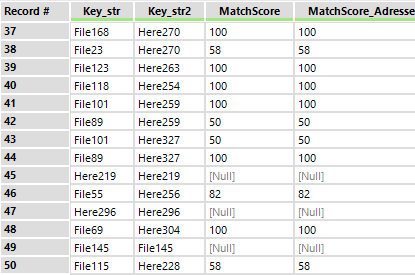
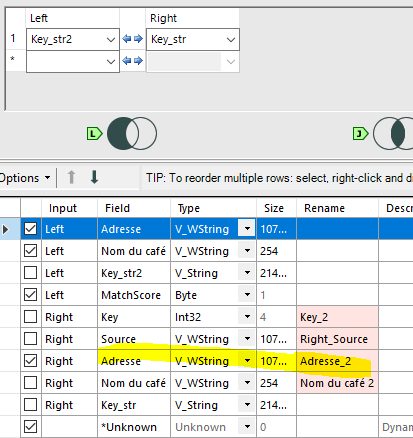
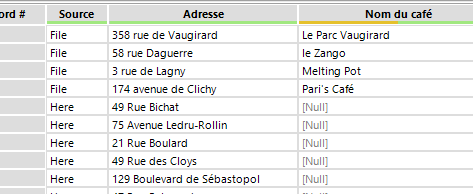
NB : c’est l’intérêt de concaténer la source devant les identifiants. Alteryx les sortiras toujours dans le même ordre : ici c’est d’abord les File, puis les Here.Si vous laissez l’identifiant uniquement, il se peut qu’il échange leur position (ID1 – ID2) ce qui peut rendre les résultats plus difficiles à lire – ou qui nécessite une étape de réordonnancement supplémentaire.
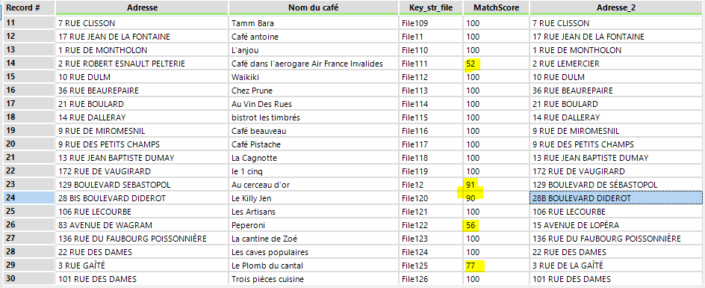
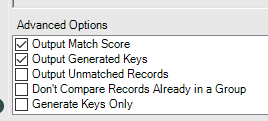
Il y a aussi les scores pour chacun des champs matchés (MatchScore_Adresse, MatchScore_Ville, etc.) puis le score global.Si vous choisissez d'ajouter comme output les lignes non matchées (Unmatched records), vous verrez des scores nulls. Ces scores peuvent être nuls si l’un des matching ‘Exact’ n’est pas respecté, si l’un des scores de matching est en-dessous du threshold ou si l’alternance des sources n’est pas respectée (ci-dessous, vous voyez qu’il propose un match entre une ligne et… elle-même).