Et si le père Noël utilisait l’IA pour voir si vous étiez un bon et sage collègue cette année ?
Alors que nous nous apprêtions à envoyer au Père Noël notre liste de souhaits pour cette année, nous avions étonnement reçu un télégramme depuis le pôle nord d’un Père Noël submergé de lettres, et soucieux de la bonne réception de ses envois : “ Ho Ho Ho, vous êtes beaucoup nombreux à vouloir des cadeaux cette année ! Mais comment je vais trouver le temps de lire toutes les revues de performance de vos managers pour voir si vous étiez un bon collègue? “
Pas d’inquiétude ! Nous pourrions peut être proposer au père Noël d’utiliser la palette Text Mining d’Alteryx, et avec un peu de magie du NLP, ses lutins sauront instantanément qui aura des cadeaux !

Qu'est ce que le Natural Language Processing ?
Le traitement du langage naturel (NLP pour Natural Language Processing) est un sous-domaine de la linguistique, de l'informatique et de l'intelligence artificielle qui s'intéresse aux interactions entre les ordinateurs et le langage humain, en particulier à la manière de programmer les ordinateurs pour traiter et analyser de grandes quantités de données en langage naturel.
Les différents types d'analyse sémantique
Il existe plusieurs méthodes et techniques de NLP qu’il faut combiner pour atteindre les résultats espérés. La valeur ajoutée du Data Analyst ou Scientist consiste donc à les manier pertinemment, voire les combiner éventuellement avec d’autres techniques de Data Science afin de proposer le modèle le plus complet et efficace.
Le 'Text Preprocessing'
Le Text Preprocessing ou prétraitement de texte, consiste à transformer le texte en un format propre et cohérent qui peut ensuite être introduit dans un modèle pour une analyse et un apprentissage ultérieurs. Les techniques de prétraitement de texte peuvent être générales ou spécialisées pour une tâche spécifique. On peut ainsi lemmatiser les mots, c’est à dire les convertir à leur racine (e.g. having, eating ⇒ have, eat), mais aussi nettoyer la ponctuation, les caractères numériques et les stop words (the, and, or, how, what…).
C'est une étape nécessaire pour faire le Topic Modelling, ou modélisation de thèmes, afin de ne pas dupliquer les résultats et hypertrophier les thèmes trouvés avec des mots inutiles à l’analyse.
La 'Lexical Extraction'
La Lexical Extraction ou l’analyse de contexte, permet d’identifier les termes relatifs à un corpus grâce à la combinaison de plusieurs techniques.
- La Tokenization, en monograms (product, customer, etc.), bigrams (customer_service, user_friendly, etc.), n-grams…
- Le Part-Of-Speech Tagging, également appelé étiquetage grammatical, processus consistant à marquer un mot dans un texte comme correspondant à une partie particulière du discours, sur la base de sa définition et de son contexte.
- La Named Entity Recognition ou la reconnaissance d'entités nommées, une sous-tâche qui vise à localiser et à classer les entités nommées mentionnées dans un texte non structuré dans des catégories prédéfinies (noms de personnes, organisations, lieux, quantités, pourcentages, etc).
- Le Sentiment Analysis ou l’analyse des sentiments, pour identifier, extraire, quantifier et étudier systématiquement les états affectifs et les informations subjectives. Tout comme l’analyse de contexte, elle combine plusieurs techniques du traitement du langage naturel, de l'analyse de texte, de la linguistique informatique et de la biométrie.
- Le Part-Of-Speech Tagging, également appelé étiquetage grammatical, processus consistant à marquer un mot dans un texte comme correspondant à une partie particulière du discours, sur la base de sa définition et de son contexte.
- La Named Entity Recognition ou la reconnaissance d'entités nommées, une sous-tâche qui vise à localiser et à classer les entités nommées mentionnées dans un texte non structuré dans des catégories prédéfinies (noms de personnes, organisations, lieux, quantités, pourcentages, etc).
- Le Sentiment Analysis ou l’analyse des sentiments, pour identifier, extraire, quantifier et étudier systématiquement les états affectifs et les informations subjectives. Tout comme l’analyse de contexte, elle combine plusieurs techniques du traitement du langage naturel, de l'analyse de texte, de la linguistique informatique et de la biométrie.
Grâce à ces techniques, nous pouvons labelliser des textes des phrases ou des mots avec des sentiments positifs (+1), neutres (0), ou négatifs (-1). En définissant des seuils (si on utilise la méthode Vader) ou indice de polarité (si on utilise TextBlob), nous pouvons extraire plusieurs autres métriques telle que la subjectivité (un indice de l’intensité du sentiment)..
Le Topic Modeling
Le Topic Modelling ou modélisation de thèmes est la méthode qui requiert une compréhension statistique plus poussée. La technique la plus utilisée est la Latent Dirichlet Allocation (LDA) qui permet d’obtenir, grâce à plusieurs paramètres, des vecteurs de mots clés avec leurs poids associés constituant un thème. Une généralisation du modèle de LDA est le modèle Hierarchical Dirichlet Process (HDP) qui ne requiert pas un choix en amont du nombre de thèmes.
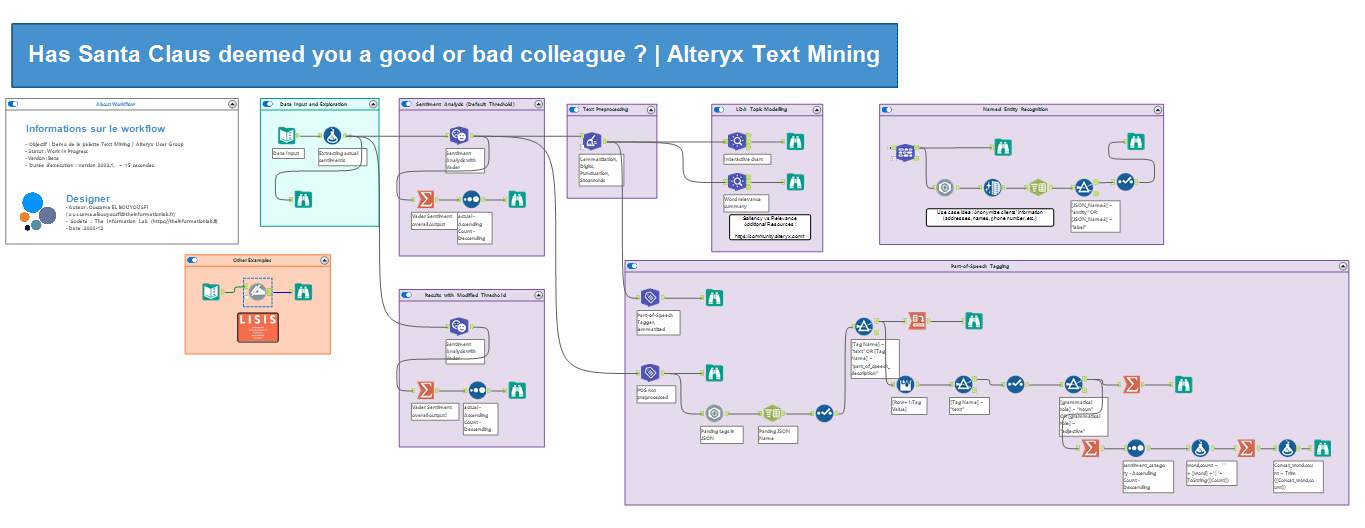
Exemple de Text Mining dans Alteryx Designer
Quel cas d’usage alors pour le père Noël sur Alteryx ? Grâce à Alteryx Designer et la palette d’outils Text Mining, le père Noël peut obtenir très rapidement des résultats assez satisfaisants, en utilisant les diverses techniques mentionnées ci-dessus.

Anonymisation des données
Ainsi, un père Noël soucieux d’abord de la confidentialité des données pourra utiliser du Named Entity Recognition pour anonymiser les données afin que ses lutins ne puissent pas voir les noms, adresses, et dates de naissance dans sa liste. En plus des détections par défaut dans Alteryx, le père Noël peut ajouter des entités définies dans l’entrée de donnée optionnelle de l’outil Named Entity Recognition (noms d’entreprise par exemple).

L’outil sort les entités détectés en JSON. Il est donc possible de les parser avec l’outil JSON Parse. La puissance du NLP est que l’outil peut détecter plusieurs formats de dates par exemple, idem pour les adresses, noms, etc…

Analyse sentimentale
Ensuite, le père Noël peut procéder à l’analyse de sentiments. Pour cela il peut simplement utiliser l’outil Sentiment Analysis, qui grâce à l’algorithme Vader, permet d’avoir un compound sentiment continu entre -1 et 1. En fonction de sa sensibilité, le père Noël peut définir le seuil maximal d’un sentiment négatif, puis le minimum pour qu’un sentiment soit considéré positif, l’entre-deux étant un sentiment ‘neutre’, et ainsi permettre à ses lutins de voir qui aura des cadeaux !

Un professionnel de la data pourra bien entendu optimiser le choix de ces seuils, en utilisant une classification ou un autre modèle de machine learning, avec un dataset où l’on connait préalablement le sentiment qu’on veut attribuer à chaque document. En guise d’exemple, nous connaissons cette donnée également, et nous savons que les seuils de classification que nous avons choisis manuellement peuvent être améliorés, même si les résultats restent globalement cohérents.

Text Pre-processing
Le père Noël peut conclure, approfondir, voir justifier ses choix avec l’analyse des thèmes. Alteryx le permet sur plusieurs langues européennes, y compris pour le nettoyage des mots (Text Pre-Processing) !

Il peut donc extraire, pour chaque document, les noms et adjectifs qui y figurent, ou voir par exemple leur fréquence par catégorie de sentiment.

Ou bien, il peut directement avoir un rapport du modèle LDA avec l’outil Topic Modelling en Interactive chart ou Word Relevance Summary. Toutes les explications techniques de l’usage et l’interprétation des résultats de l’outil peuvent être lues dans cet article de blog : https://community.alteryx.com/t5/Data-Science/Getting-to-the-Point-with-Topic-Modeling-Part-3-Interpreting-the/ba-p/614992

Enfin, on peut aussi agir sur les fautes d’orthographe, et les différentes formes qui peuvent correspondre à un seul format principal de thème, en combinant Part-of-Speech Tagging, Tokenization, et d’autres métriques statistiques. C’est ce qu’on fait des chercheurs français du Laboratoire Interdisciplinaire Sciences Innovations Sociétés (LISIS).

A vous la magie de Noël mais aussi de l’Alteryx Intelligence Suite !
Besoin d’aide avec Alteryx ?
Vous êtes curieux de savoir comment Alteryx peut s’intégrer dans votre pratique de l’analyse ? Où déjà utilisateur et vous cherchez à progresser davantage ? Ou bien, un utilisateur débutant et vous souhaitez vous former ?
Notre équipe se fera une joie d’en avec vous ! Faites-nous part de vos besoins en nous contactant à contact@theinformationlab.fr !